SharePoint Markdown to PDF: a limit test with Agents and Flow Studio MCP
Quick Map
For
- Power Automate devs
- agent experimenters
You'll see
- SharePoint Markdown file storage
- Graph PDF conversion redirects
- DOCX conversion failure

Update: I wrote a follow-up with the full working setup and compatibility results: Convert Markdown to PDF with Power Automate.
Microsoft announced native Markdown support in SharePoint and OneDrive.
That is interesting for humans, but it is very interesting for agents.
So I put on my Flow Ninja hat and asked my agent, today, it’s Codex today, to limit test this.
Of course, with a flow, via our Flow Studio MCP.
The question
I asked:
microsoft says markdown is a first class file in onedrive and sharepoint
I want you to write a flow create and save a markdown file to a site, you can use the default document library
then try to convert that markdown file to pdf or doc
The test was deliberately practical:
- Create a Markdown file in SharePoint.
- Confirm SharePoint accepts it as Markdown.
- Try to convert it to PDF.
- Try to convert it to DOCX.
- See what actually works.
First attempt: SharePoint HTTP
Codex created a flow:
It worked for 2m 49s.
Done. I created and started this flow:
MCP Demo - Markdown SharePoint Convert Test
Flow ID:
[redacted]It does this:
- HTTP trigger accepts optional
title,fileName, andmarkdown.- Creates a
.mdfile in SharePoint:https://johnliu365.sharepoint.com/->/Shared Documents- Attempts conversion using SharePoint drive content endpoints:
?format=pdf?format=docx- Returns the statuses in the HTTP response.
I triggered it with
markdown-conversion-smoke-test.md.
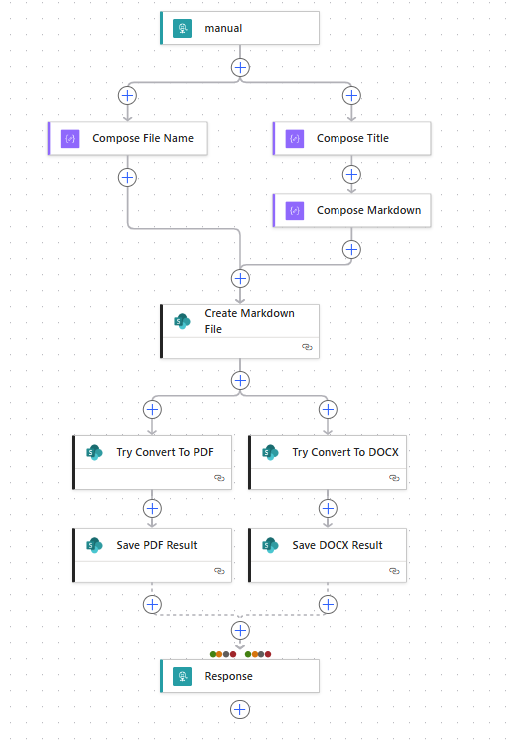
The result:
Markdown file creation: Succeeded
Created file media type:
text/markdownPDF conversion attempt: Failed, but SharePoint returned HTTP
302, which suggests the PDF conversion endpoint redirects to a generated content stream. The Power Automate SharePoint HTTP action treats that redirect as failure and did not expose/save the PDF body.DOCX conversion attempt: Failed, HTTP
406, so DOCX is not accepted from that endpoint for Markdown.
So the first finding was:
SharePoint accepts Markdown as a first-class stored file, but the standard SharePoint connector path did not directly save it as PDF or DOCX.
PDF looked very close because of the 302. The conversion was not really dead; the connector just did not expose the redirected content stream in a useful way.
DOCX looked unsupported.
The flow URL
I asked Codex for the flow URL:
Here you go:
https://make.powerautomate.com/environments/[redacted]/flows/[redacted]/detailsFlow name: MCP Demo - Markdown SharePoint Convert Test
That first flow was useful because it showed the shape of the problem.
The Markdown file itself was fine.
The conversion path was the interesting part.
Second attempt: follow the 302
Then I asked:
can you try using Office 365 Send HTTP request to convert and follow the 302?
Codex came back with the better answer:
This time it worked for 4m 16s.
Yes, that worked.
I updated/created this flow:
https://make.powerautomate.com/environments/[redacted]/flows/[redacted]/detailsWhat it does now:
- Uses Office 365 Groups - Send an HTTP request against Graph.
- Resolves the SharePoint root site ID.
- Calls Graph conversion:
/drive/root:/markdown-conversion-smoke-test.md:/content?format=pdf- Office 365 HTTP receives the expected
302and exposes theLocationheader.- The flow follows that pre-authenticated media URL with built-in HTTP.
- Saves the result back to SharePoint as:
markdown-conversion-smoke-test-office365-http.pdfRun result:
- Graph conversion request:
302- Redirect follow:
200- Content type:
application/pdf- Save to SharePoint: Succeeded
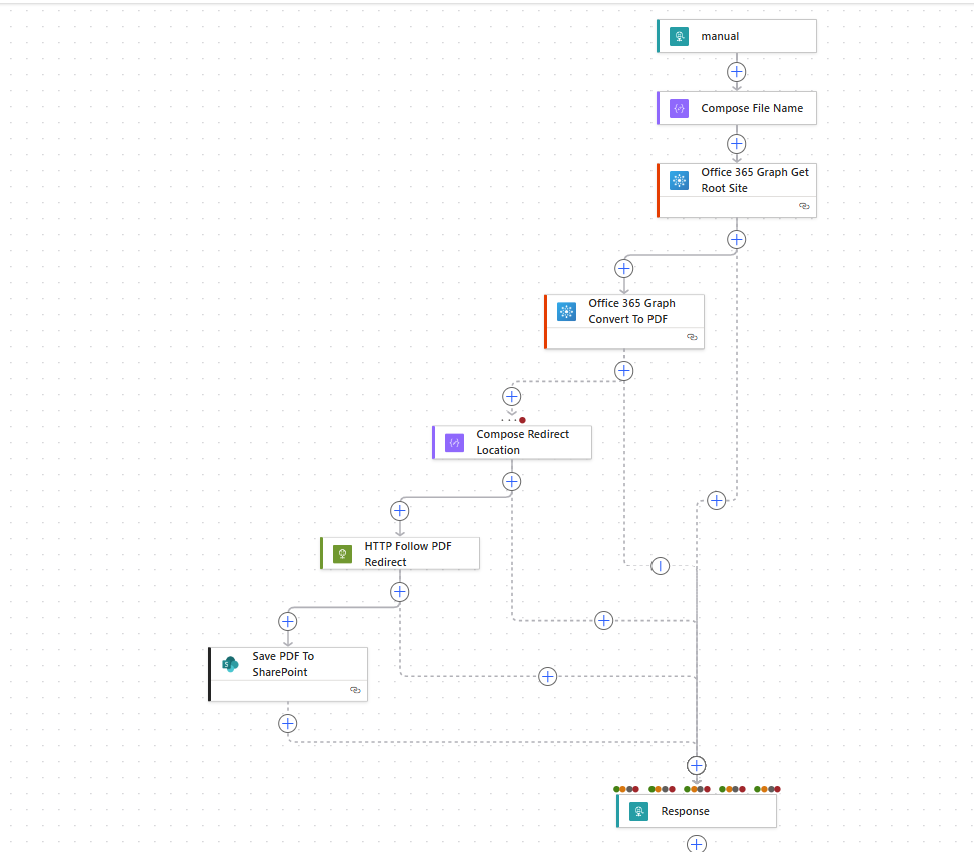
So we have a new way to generate PDF. Nifty.
What worked
Markdown file creation worked.
SharePoint stored it as:
text/markdownGraph conversion to PDF worked when the flow used an HTTP action that could see the Location header and follow the redirect.
The final PDF was saved back into SharePoint successfully. That means we can create Markdown from an agent, store it in SharePoint, and turn it into PDF with a Power Automate flow.
What did not work
DOCX conversion did not work in this test.
The conversion endpoint returned:
406Why this matters for agents
I was actually so thrilled. I’m able to ask the agent to research, and it built the flow and confirmed it with only 2 prompts.
Create a flow. Create a file. Test conversion. Inspect status codes. Try a different connector. Follow the redirect. Save the result. Report what happened.
An agent is good at pushing through that loop. Confirm the new Flow Ninja hack.
The finding
Markdown in SharePoint and OneDrive is real and useful.
.mdcreation in SharePoint: yes- media type:
text/markdown - PDF conversion through Graph redirect: yes
- PDF save back to SharePoint: yes
- DOCX conversion through this endpoint: no
That is a pretty good result.
Third attempt: make the flow blog-postable
Then I looked at the flow and said:
btw that’s an awful looking catch block can you do something about that? I need to write a good blog post man.
Codex cleaned it up:
This cleanup took 51s.
Yep. I cleaned it up into a much more blog-postable shape.
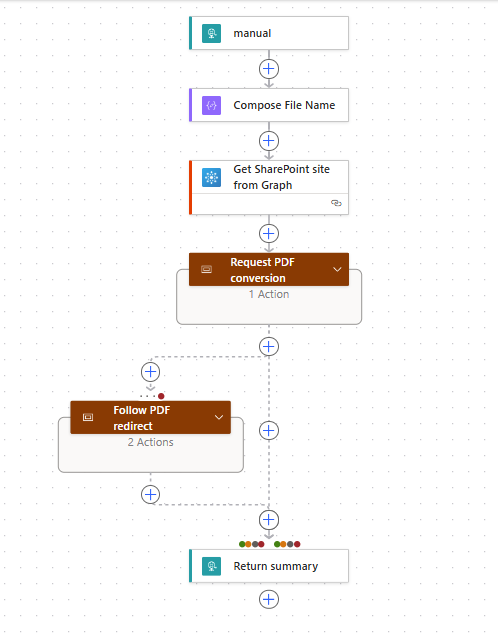
The flow now reads like this in the designer:
Compose_File_NameGet_SharePoint_site_from_GraphRequest_PDF_conversionscopeFollow_PDF_redirectscopeReturn_summaryInside
Follow_PDF_redirect, it now explicitly checks that Graph returned the expected302and aLocationheader before downloading the generated PDF. If it does not, it terminates with a clearUnexpectedGraphConversionResponsemessage instead of looking like a weird generic catch block.I reran it and it still works:
- Graph request:
302- PDF redirect followed: Succeeded
- PDF download:
200- Content type:
application/pdf- Save to SharePoint: Succeeded
Discussions